

Cuando comencé a estudiar acerca de los famosos microservicios, todo era nuevo y sigue siendo nuevo, todo me sorprendía y me sigue sorprendiendo, cuando leí acerca de las aplicaciones distribuidas, teorema CAP, mi cabeza daba vueltas de sólo imaginar como construir las que de una u otra manera se han convertido en el “estándar” para la construcción de aplicaciones que permitan escalar y un sin número de argumentos sobre sus beneficios . Sin embargo, desde la aparición de los microservicios, también con ellos vienen muchos desafíos, muchos muchos desafíos, entre todos ellos me gustaría comentarles acerca de La Observabilidad.

La observabilidad nace a partir de la necesidad de conocer el estado de nuestros servicios o aplicaciones en un entorno distribuido, esta misma nos permitirá saber en todo momento cuál es el real estado de nuestra aplicación y no sólo de una, sino miles de aplicaciones desplegadas, donde cada segundo y minuto que corren nuestras aplicaciones son vitales de cara al negocio, necesitamos saber la degradación del servicio y saber que todo esta funcionando correctamente o al menos saber como esperamos que funcione. Entender porque fallan o qué podría llevar a una falla en nuestras aplicaciones o servicios, nos permite estar preparados ante los desafíos que enfrentan las organizaciones modernas, pero eso lo dejamos para otro articulo :D. Si podemos hacer todo lo anterior, también nos ayuda a cumplir o no un SLA (Service Level Agreement).
Para ser más claro en que nos brinda la observabilidad, pensemos en que la adopción de los microservicios dada su naturaleza distribuida, nos implica un nuevo conjunto de problemas que podemos ver simplemente en el hecho de querer revisar logs de uno de los microservicios que tenemos desplegados como parte de un sistema mayor. Se imaginan si tenemos más de cien microservicios corriendo y tener la responsabilidad de mirar cada uno de esos microservicios mediante sus logs, entrando uno a uno para revisar si tuvo algún problema o si puede experimentar problemas a futuro, sería completamente inmanejable la cantidad de tiempo que consumiría al equipo, no nos permitiría adelantarnos a problemas o desastres, no podríamos tomar desiciones o simplemente no tendríamos indicadores de cara al negocio para determinar si una iniciativa de desarrollo de un nuevo producto, tuvo el impacto que se esperaba en el mercado. Cuando trabajamos con sistemas distribuidos queremos saber donde está el problema y solucionarlo tan pronto como sea posible, ojalá antes de afectar a otros sistemas que pueden estar relacionados, afectar a usuarios o clientes , por eso necesitamos una observabilidad que vaya mucho más allá de revisar simples logs, necesitamos una observabilidad para anticiparnos y conocer tanto de servicios como también de la infraestructura.
La observabilidad nos permite responder o al menos va en esa dirección, a las siguientes preguntas:
- ¿Porque está abajo el servicio X?
- ¿Qué estuvo mal durante el despliegue X?
- ¿Porqué el sistema se ha degradado en rendimiento?
- ¿El problema en el servicio X afecta a usuarios específicos o a la organización completa?
Existen muchas herramientas que nos permiten observar nuestras aplicaciones mediante dashboards o paneles que nos permiten visualizar la información que nos proveen las aplicaciones o servicios, entre ellas Elastic, Splunk, etc., para todo ello debemos tener un equipo dedicado que nos oriente sobre que se debe construir para obtener esa tan anhelada observabilidad, que esperamos ver en nuestros logs, que métricas deseamos obtener, cuales son los eventos que nos interesan conocer, diferenciar por dominio de negocio, hay mucho paño que cortar ahí. Pero bueno, con todo ello podemos realmente estar más cerca de un verdadero SLA, SLO y SLI. (también lo veremos más adelante, porque es material para un articulo o varios artículos completos)
Dentro de la observabilidad tenemos muchas cosas que conocer y otras nos acompañan por bastante tiempo, los siguientes son datos de telemetría y ellas son: métricas, los logs y la trazabilidad, estás también son conocidas por ser los pilares de la observabilidad y la clave en sistemas distribuidos. Pero veamos que es cada uno de ellos para que aprendamos y luego apliquemos en nuestros proyectos 😉
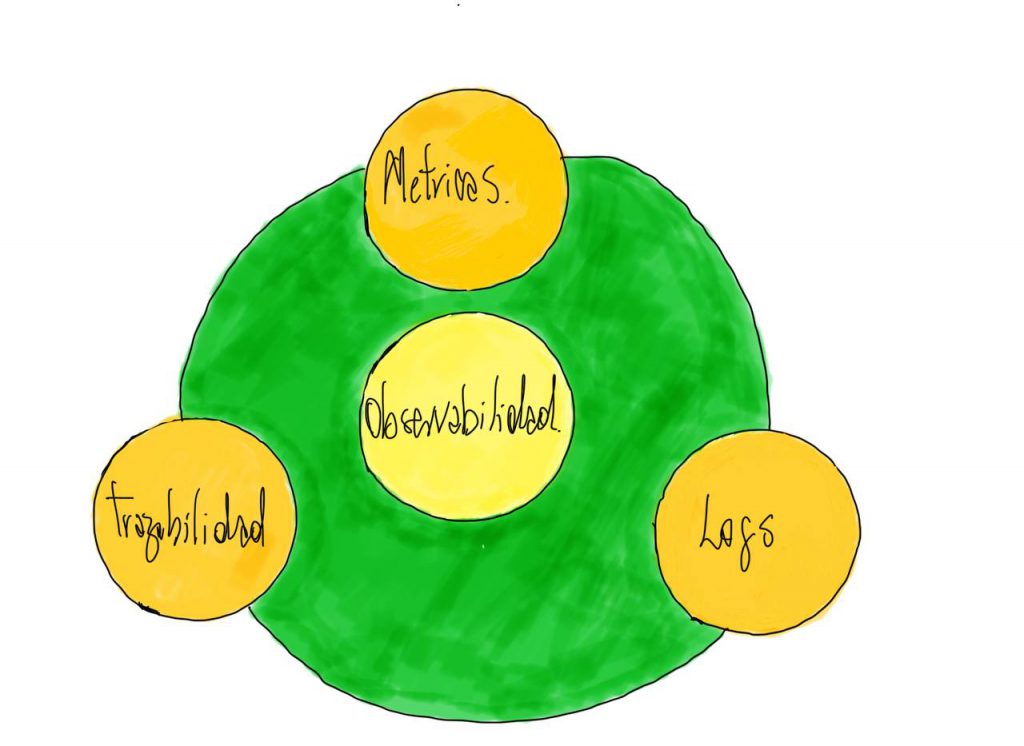
Logs
Logs son aquellos que vemos cuando nuestro código se ejecuta y corre, corre y corre nuestra aplicación, los logs son lineas de texto estructuradas y no estructuradas, estas líneas de texto comienzan a registrar los eventos que suceden dentro de una aplicación. Los logs nos ayudan a visualizar posibles errores en nuestro código o flujo de nuestra aplicación, errores que normalmente son impredecibles hasta que hacemos correr nuestra aplicación. Hay muchas librerías y frameworks que nos ayudan a instrumentalizar nuestras aplicaciones, entre ellas podemos hablar de Log4J y Logback para Java, Winston y Bunyan para Node, Logrus para Golang, bueno cada lenguaje tendrá una o más alternativas para instrumentar las aplicaciones con el fin de generar logs. Los logs finalmente nos entregan bastante información, por ejemplo fechas y hora cuando ha ocurrido un evento, nos entregan información vital para determinar donde tuvimos incidentes de seguridad en bases de datos, caches u otra parte de nuestra aplicación o infraestructura.


Métricas
Respecto a las métricas, podemos decir que son una representación numérica de los datos que se usan para determinar el comportamiento de nuestras aplicaciones, servicios o componente a lo largo del tiempo. Las métricas pueden contener un conjunto de atributos, estos pueden ser nombre, valor, etiqueta y hora, las que posteriormente transmiten información acerca de SLA, SLO y SLI. A diferencia de un registro de realizado mediante un log, que nos registra eventos específicos, las métricas son un valor medido derivado del rendimiento del sistema. Las métricas nos ayudan en tiempo real porque podemos ponerlas fácilmente en relación a los componentes de la infraestructura para obtener una visión completa del estado y el rendimiento de nuestros sistemas, aplicaciones y/o servicios. Podemos recopilar métricas sobre el tiempo de actividad del sistema, el tiempo de respuesta, la cantidad de solicitudes por segundo y cuánta potencia de procesamiento o memoria está usando una aplicación, con toda esta información podemos utilizar estas métricas para activar alertas cada vez que un valor del sistema supera un umbral especificado.
Al igual que pasa con los logs, también tenemos librerías y gran número de frameworks que nos ayudan con la obtención de estás métricas, sólo para mencionar algunas, tenemos Micrometer el cual es una librería de instrumentación para métricas especialmente construida para Spring Boot 2.0.

Otro para mencionar; me parece que es una gran iniciativa, OpenTelemetry (OpenTracing y OpenCensus se fusionaron y formaron este proyecto) , este es un proyecto que facilita la instrumentación de aplicaciones pensando en la estandarización de las métricas y entregando soporte para más de un lenguaje de programación, entre ellos C++, Go, Python, Java, Rust, .Net, Javascript.

Trazabilidad
Para ver y comprender el ciclo de vida completo de una solicitud/petición/request/acción en varios sistemas, necesita otra forma de observabilidad llamada seguimiento, trazabilidad o tracing. Una traza representa el viaje completo de una solicitud o acción a medida que se mueve a través de todos los nodos de un sistema distribuido. Los seguimientos nos permiten observar sistemas, especialmente aplicaciones en contenedores, arquitecturas sin servidor (serverless) o arquitectura de microservicios. Al analizar los datos de rastreo, nosotros podemos medir el estado general del sistema, identificar cuellos de botella, identificar y resolver problemas más rápido y priorizar áreas de alto valor para optimización y mejoras.
La trazabilidad es un pilar esencial de la observabilidad porque proporcionan contexto para los otros componentes de esta misma. Por ejemplo, puede analizar un seguimiento para identificar las métricas más valiosas según lo que está tratando de lograr o los registros relevantes para el problema que está tratando de solucionar.

La trazabilidad es adecuada para depurar y monitorear aplicaciones complejas que compiten por recursos. La trazabilidad proporciona respuestas rápidas a las siguientes preguntas en entornos de software distribuidos:
¿Qué servicios tienen un código ineficiente o problemático que debe priorizarse para la optimización?
¿Cómo es el estado y el rendimiento de los servicios que componen una arquitectura distribuida?
¿Cuáles son los cuellos de botella de rendimiento que podrían afectar la experiencia general del usuario final?

Los logs, la trazabilidad y las métricas tienen un propósito único, todos trabajan juntos para ayudarnos a comprender mejor el rendimiento y el comportamiento de los sistemas distribuidos. Si nuestra organización ya usa arquitectura de microservicios o sin servidor, o si planea adoptar contenedores y microservicios, una combinación de todos los datos de telemetría proporcionará la información detallada necesaria para comprender y depurar nuestro sistema.
Este tema de la observabilidad es muy extenso y hay mucho material para compartir con ustedes, pronto comenzaré a construir los siguientes artículos en los cuales veremos ejemplos de instalaciones de diferentes herramientas de observabilidad, implementación de microservicios con formatos de logs y métricas. La idea fundamental de esto es compartir el conocimiento y lograr hacer llegar estas herramientas a ustedes para que apliquen estas mismas en sus iniciativas personales o en su lugar de trabajo.
Espero que lo disfruten, un abrazo ;-).